01
Space Odyssey – Space Tunnel Runner
Space Odyssey est un jeu 3D palpitant développé en Python avec le framework Kivy. Il plonge le joueur dans un tunnel spatial infini où il doit piloter un vaisseau futuriste en évitant les obstacles et les parois du tunnel à toute vitesse. Le gameplay est fluide et nerveux, avec des graphismes en perspective 3D, des effets sonores immersifs et une bande-son spatiale originale. Grâce à son moteur optimisé, le jeu fonctionne à 60 FPS et offre une expérience fluide sur PC comme sur mobile.
Le joueur peut contrôler le vaisseau avec les flèches directionnelles (sur desktop) ou par simple toucher (sur mobile). Le score augmente à mesure que l'on avance, et un écran de fin affiche les performances. L’interface utilisateur est entièrement conçue avec Kivy, incluant des animations, des menus interactifs, et une gestion des collisions efficace.
Ce projet met en œuvre des transformations mathématiques pour simuler la perspective 3D, des effets visuels dynamiques, des sons événementiels, et une architecture modulaire du code (séparant logique, interface, contrôles et audio). Idéal pour démontrer mes compétences en développement Python, conception UI, logique de jeu et optimisation multiplateforme.
Python, Kivy, Audio FX, 3D Perspective, Game Loop, UI/UX
02
Phone Price Prediction - Application de Prédiction IA
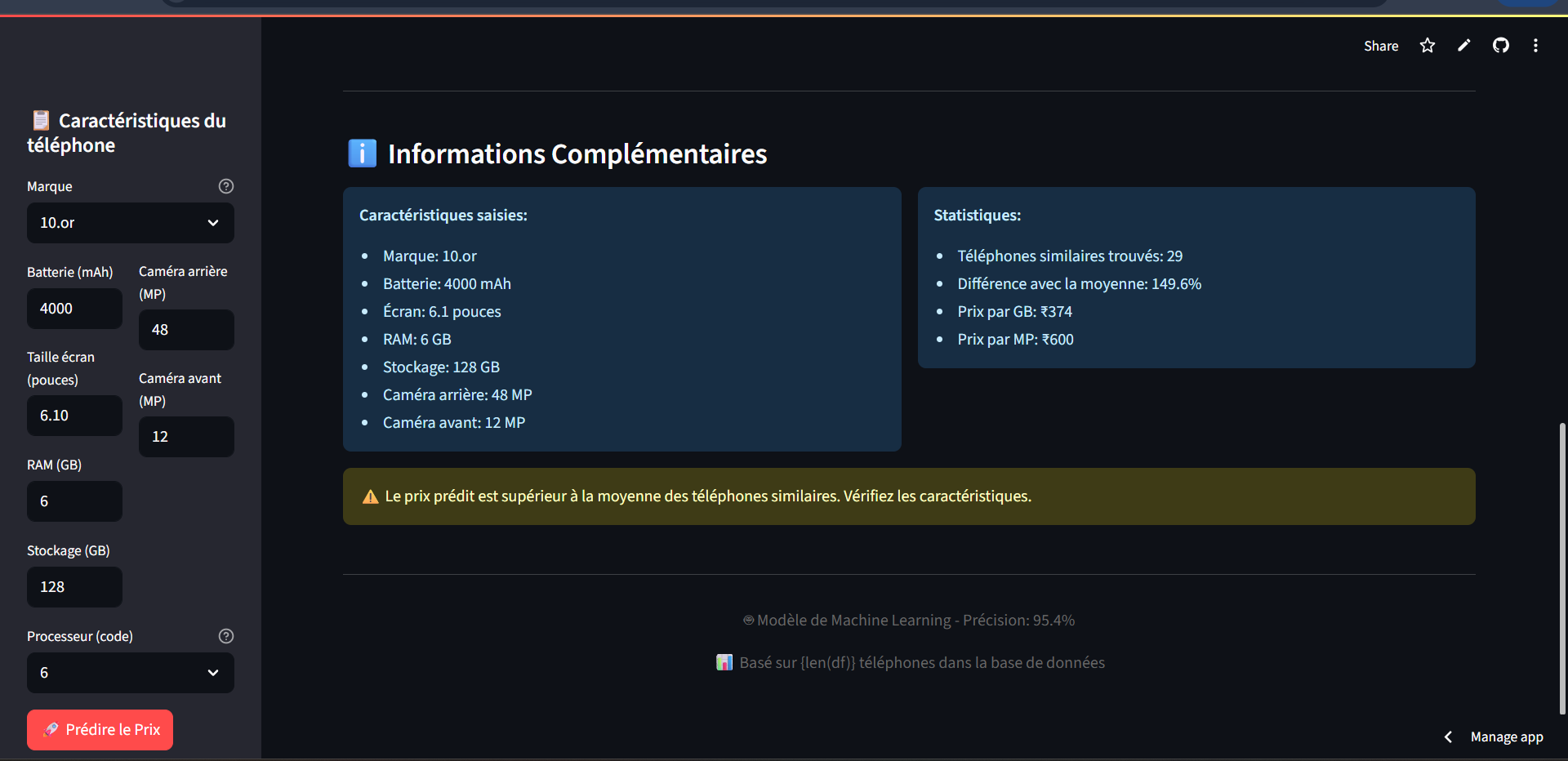
Ce projet met en œuvre une application web interactive permettant d’estimer le prix d’un smartphone à partir de ses caractéristiques techniques. Grâce à un modèle de machine learning entraîné sur un dataset réel, l'utilisateur peut entrer des données comme la marque, la batterie, la RAM, le processeur ou la taille d'écran, et obtenir instantanément une prédiction du prix.
L’interface, développée avec Streamlit, est simple, intuitive et accessible en ligne. Elle intègre un affichage dynamique de la prédiction sous forme de graphique, renforçant l’expérience utilisateur.
L’ensemble du pipeline de machine learning est optimisé : nettoyage des données, encodage des variables, normalisation, entraînement d’un modèle de régression (Random Forest), et sauvegarde des artefacts via Pickle/Joblib.
Ce projet démontre mes compétences en Data Science, en développement d’application IA, ainsi qu’en déploiement web avec Streamlit Cloud.
Python, Pandas, Scikit-learn, Streamlit, Joblib
03
Lalànako
LALÀNAKO est un assistant juridique intelligent qui permet de :
- visualiser un texte juridique existant,
- faire défiler (scroll) l’article ou la notion,
- obtenir une explication simple en malagasy sur demande,
- sans donner de conseils juridiques illégaux ni personnalisé
React.js, FastAPI, LLM Gemini
04
Projet ETL – Analyse des Ventes & Comportement Client en Supermarché
Ce projet met en place un pipeline ETL complet couplé à un entrepôt de données décisionnel,
conçu pour analyser les ventes, le comportement client et les performances produit d'une
chaîne de supermarchés française. Il repose sur un schéma en étoile (Star Schema) avec
une table de faits centrale (50 000 transactions) reliée à 4 dimensions : Temps, Produit,
Client et Magasin.
Le pipeline couvre les trois phases ETL : l'Extraction des données (générées de façon
réaliste via Faker et NumPy), la Transformation incluant le nettoyage, la validation,
l'enrichissement (tranches d'âge, remises fidélité de 0 à 15%, surrogate keys), et enfin
le Chargement ordonné dans PostgreSQL avec indexation pour des performances optimisées
(gain de 10x à 100x sur les requêtes).
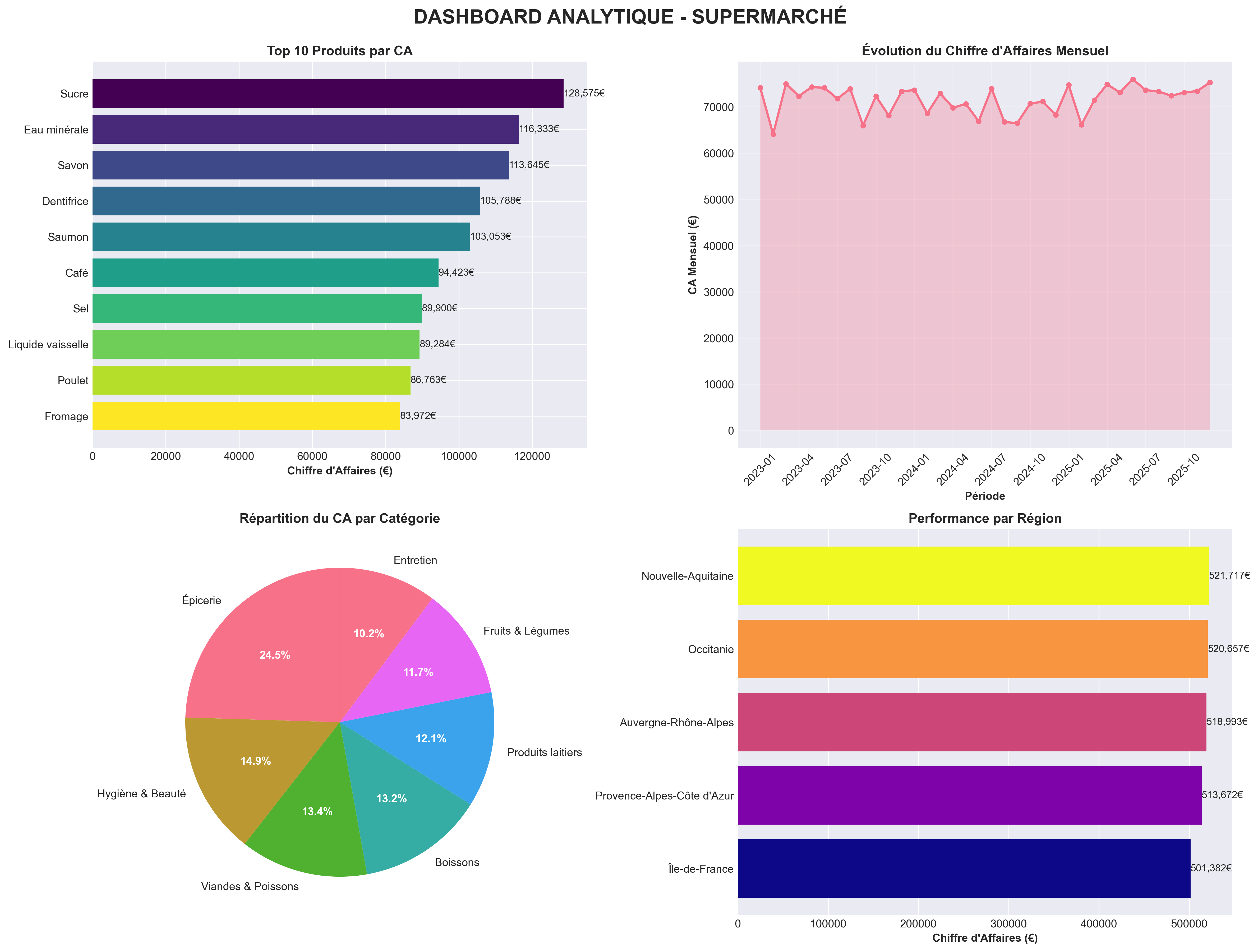
Des analyses OLAP multidimensionnelles ont été réalisées via des requêtes SQL complexes :
Top 10 produits par chiffre d'affaires, évolution mensuelle du CA, analyse de la saisonnalité
et segmentation client (Bronze, Silver, Gold, Platinum). Les résultats sont restitués sous
forme de tableaux de bord interactifs avec Matplotlib et Seaborn, démontrant des compétences
complètes en ingénierie de données, modélisation dimensionnelle et analyse décisionnelle.
Python, PostgreSQL, Pandas, SQLAlchemy, Matplotlib, Seaborn, Faker, Jupyter Notebook, SQL OLAP, Star Schema
05
Vary-IA — Système Hybride de Diagnostic des Maladies du Riz
Vary-IA est un système d'intelligence artificielle hybride conçu pour diagnostiquer
les maladies des feuilles de riz à Madagascar, depuis un simple smartphone Android.
Il combine deux sources d'information : la photo d'une feuille de riz et les données
climatiques des 7 derniers jours, afin d'identifier 4 maladies critiques —
Bacterialblight, Blast, Brownspot et Tungro — qui ravagent jusqu'à 40% des rendements
chaque année.
L'architecture hybride repose sur deux branches complémentaires : un CNN MobileNetV2
(Transfer Learning + Fine-Tuning) pour l'analyse visuelle des feuilles, et un
BiGRU bidirectionnel pour l'analyse des séquences climatiques (température et humidité).
Les deux branches fusionnent leurs vecteurs de features pour produire un diagnostic
final avec un niveau de confiance. Le modèle atteint 99.55% d'accuracy pour le CNN
seul et 99.04% pour le modèle hybride, entraînés sur 26 682 images (augmentation ×5)
et 2 000 entrées météo réelles.
Un Denoising Autoencoder (DAE) est intégré en bonus pour améliorer la qualité des
images dégradées sur le terrain (flou, bruit, contre-jour). Les modèles sont convertis
en TFLite (~12 MB après quantization INT8) pour un déploiement offline sur Android,
avec une inférence inférieure à 300ms. Ce projet illustre mes compétences en Deep
Learning multimodal, Transfer Learning, traitement de séries temporelles et
déploiement mobile au service d'un impact social concret.
Python, TensorFlow, MobileNetV2, BiGRU, Transfer Learning, TFLite, Google Colab, NumPy, Matplotlib
06
Gender Classification — CNN Benchmarking & Transfer Learning
Ce projet implémente et compare six architectures de réseaux de neurones convolutifs
(CNN) pour la classification binaire du genre (Homme / Femme) à partir d'images
faciales issues du dataset CelebA (1 813 images, 128×128). L'objectif principal est
d'évaluer les différences de performance entre des CNN entraînés from scratch et des
modèles pré-entraînés via Transfer Learning, sur un dataset de taille limitée.
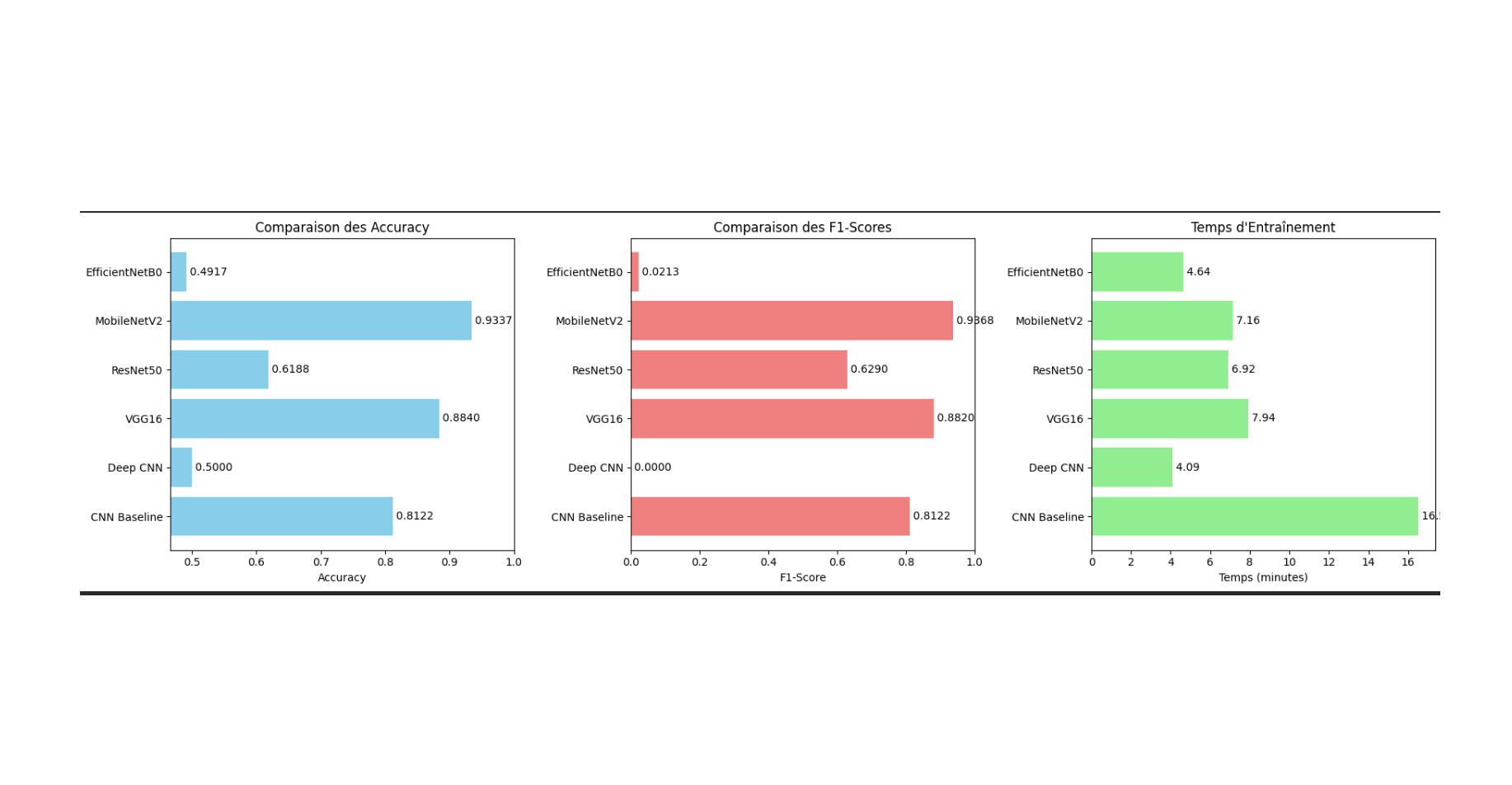
Deux CNN from scratch (Baseline CNN et Deep CNN avec Batch Normalization) ont été
comparés à quatre architectures pré-entraînées : VGG16, ResNet50, MobileNetV2 et
EfficientNetB0, toutes fine-tunées pour la classification binaire. Le pipeline
d'entraînement inclut augmentation de données (rotation, zoom, flips), optimiseur
Adam, EarlyStopping et ReduceLROnPlateau. Les résultats confirment que le Transfer
Learning surpasse significativement les CNN from scratch en termes de convergence,
de généralisation et de stabilité.
Les architectures légères MobileNetV2 et EfficientNetB0 offrent le meilleur compromis
précision / coût computationnel, tandis que les CNN from scratch nécessitent une
régularisation soignée pour éviter le surapprentissage. Ce projet illustre une
méthodologie d'expérimentation rigoureuse et reproductible, démontrant mes compétences
en Computer Vision, benchmarking de modèles Deep Learning et fine-tuning de
backbones CNN pré-entraînés.
Python, TensorFlow, Keras, VGG16, ResNet50, MobileNetV2, EfficientNetB0, Transfer Learning, Google Colab, Matplotlib